Lab 06 요약: Hadoop과 Spark를 활용한 빅데이터 처리
Lab 06에서는 Hadoop과 Spark를 사용해 대규모 데이터 처리와 분산 컴퓨팅 환경에서의 작업을 실습합니다. 실습은 두 부분으로 구성되며, 첫 번째는 Hadoop을 사용한 HDFS 설정과 MapReduce 작업, 두 번째는 Spark를 사용한 PySpark 프로그램 작성 및 비교 분석입니다.
Part 1: Hadoop 설정 및 MapReduce 실습
1. Hadoop 클러스터 구성
• 인스턴스 구성:
• 1개의 NameNode와 3개의 DataNode로 구성된 클러스터 설정.
• 각 인스턴스는 Ubuntu Server 16.04 AMI를 사용.
• 최소 사양:
• 2 vCPU, 4GB RAM, 12GB 디스크.
• 네트워크 설정:
• VPC에서 서브넷과 보안 그룹 설정.
• ssh를 통해 비밀번호 없이 접속하도록 설정.
2. Hadoop 설치
• 필수 소프트웨어 설치:
• Java (OpenJDK 1.8) 설치.
• Hadoop 2.10.1 다운로드 및 설치.
• 환경 변수 설정:
• JAVA_HOME, HADOOP_HOME을 .profile에 추가.
3. Hadoop 구성 파일 수정
• 핵심 파일:
• core-site.xml: NameNode IP와 HDFS 경로 설정.
• hdfs-site.xml: 데이터 복제와 저장소 디렉토리 설정.
• mapred-site.xml: MapReduce 프레임워크 이름 지정.
• yarn-site.xml: YARN 설정 추가.
4. HDFS 및 YARN 시작
• hdfs namenode -format으로 파일 시스템 포맷.
• start-dfs.sh와 start-yarn.sh로 데몬 실행.
• hdfs dfsadmin -report로 클러스터 상태 확인.
5. MapReduce 작업
• Pi 계산 프로그램 실행:
• hadoop jar hadoop-mapreduce-examples-2.10.1.jar pi 10 1000.
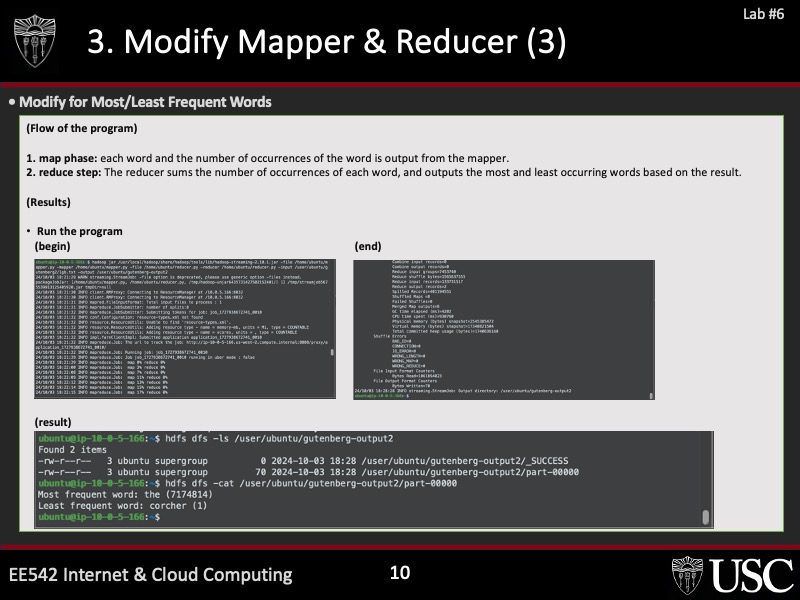
• Python 기반 WordCount 프로그램 작성:
• mapper.py와 reducer.py를 작성하여 단어 빈도 계산.
• HDFS에서 데이터 저장 및 출력.









Part 2: Spark를 활용한 분산 데이터 처리
1. PySpark 설치 및 실행
• 환경 설정:
• Docker를 사용하여 Jupyter Notebook과 PySpark 설치.
• AWS EC2에서 Amazon Linux 2 AMI 사용.
• docker run 명령으로 PySpark 환경 구축.
• Spark 로컬 실행:
• 단일 노드에서 테스트.
2. AWS EMR 클러스터 구성
• Spark 클러스터 생성:
• 2개의 c5.xlarge 인스턴스로 구성된 EMR 클러스터 생성.
• 클러스터 관리자 자동 설정.
• 노트북 설정:
• S3 버킷을 데이터 소스로 설정.
• EMR에 연결된 JupyterLab에서 PySpark 실행.
3. MapReduce와 Spark 비교
• 작업:
• WordCount와 빈도 계산 프로그램을 Spark로 구현.
• 동일한 작업을 Hadoop과 Spark에서 실행하여 성능 비교.
• 성능 비교:
• 워커 노드 수에 따른 확장성 비교.
• 처리 속도 및 리소스 사용량 분석.








결과 및 분석
1. Hadoop vs Spark:
• Spark는 메모리 기반 처리로 Hadoop보다 빠른 성능을 제공.
• 워커 노드 수가 증가할수록 Spark의 확장성이 더 우수.
2. MapReduce 작업 최적화:
• Hadoop과 Spark 모두 Python 기반 Mapper와 Reducer 사용.
• ASCII 문자 범위(33~122) 내에서 빈도 계산.

제출 요구 사항
1. 소스 코드:
• Hadoop과 Spark에서 동작하는 Python 스크립트.
2. 결과 보고서:
• 성능 비교 그래프 포함.
3. 데모 비디오:
• 클러스터 설정 및 작업 실행 과정.
(mapper.py)
#!/usr/bin/env python
"""mampper.py"""
import sys
def read_input(file):
for line in file:
# Split the line into words
yield line.split()
def main(separator='\t'):
# Input comes from STDIN (standard input)
data = read_input(sys.stdin)
for words in data:
# Write the results to STDOUT (standard output);
# tab-delimited; the trivial word count is 1
for word in words:
print('%s%s%d' % (word, separator, 1))
if __name__ == "__main__":
main()
(reducer.py)
# #!/usr/bin/env python
# """reducer.py"""
"""reducer.py"""
from itertools import groupby
from operator import itemgetter
import sys
def read_mapper_output(file, separator='\t'):
for line in file:
# Split the input from the mapper into word and count
yield line.rstrip().split(separator, 1)
def main(separator='\t'):
max_count = 0
min_count = sys.maxsize
max_words = []
min_words = []
# Input comes from STDIN (standard input)
data = read_mapper_output(sys.stdin, separator=separator)
for current_word, group in groupby(data, itemgetter(0)):
try:
total_count = sum(int(count) for current_word, count in group)
# Track the words with the highest count
if total_count > max_count:
max_count = total_count
max_words = [current_word] # Reset list and add the new word
elif total_count == max_count:
max_words.append(current_word) # Append word if it has the same max count
# Track the words with the lowest count
if total_count < min_count:
min_count = total_count
min_words = [current_word] # Reset list and add the new word
elif total_count == min_count:
min_words.append(current_word) # Append word if it has the same min count
except ValueError:
# If count was not a number, silently discard this item
pass
# Output the most frequent words and least frequent words
if max_words and min_words:
print("Least frequent words: {} ({} occurrences)".format(', '.join(min_words), min_count))
print("Most frequent words: {} ({} occurrences)".format(', '.join(max_words), max_count))
if __name__ == "__main__":
main()'Learn > '24_Fall_(EE542) Internet&Cloud Computin' 카테고리의 다른 글
| (LAB 08) Android-based IoT Network with Nod-Red and Thingsboard IO on Cloud (0) | 2025.01.09 |
|---|---|
| (LAB 07) Final Project Brainstorming and Interviews (0) | 2025.01.09 |
| (LAB 05) Fast, Reliable File Transfer with Custom TCP/IP (0) | 2025.01.09 |
| (LAB 04) Fast, Reliable File Transfer (0) | 2025.01.09 |
| (LAB 03) Network Measurement (0) | 2025.01.09 |