강의 요약: EE542 Lecture 20 - Embeddings and Vectorizations
이번 강의는 **임베딩(Embeddings)**과 **벡터화(Vectorizations)**를 중심으로, 자연어 처리(NLP)와 데이터 표현의 주요 개념과 기술을 다루었다. Word2Vec과 같은 기법을 통해 단어와 문서의 의미를 수치적 벡터로 표현하고, 이를 다양한 NLP 작업에 활용하는 방법이 강조되었다.
주요 내용
1. 임베딩의 필요성
• 텍스트를 수치 데이터로 변환해야 머신러닝 모델에 활용 가능.
• One-Hot Encoding:
• 단어를 길이 $N$의 벡터로 표현하며, 단 하나의 값만 1이고 나머지는 0.
• 공간 비효율적이며 단어 간 관계를 표현하지 못함.
• Bag of Words (BoW):
• 문서에서 단어의 발생 횟수를 기반으로 표현.
• 단어 순서를 고려하지 않아 문맥 표현이 불가능.

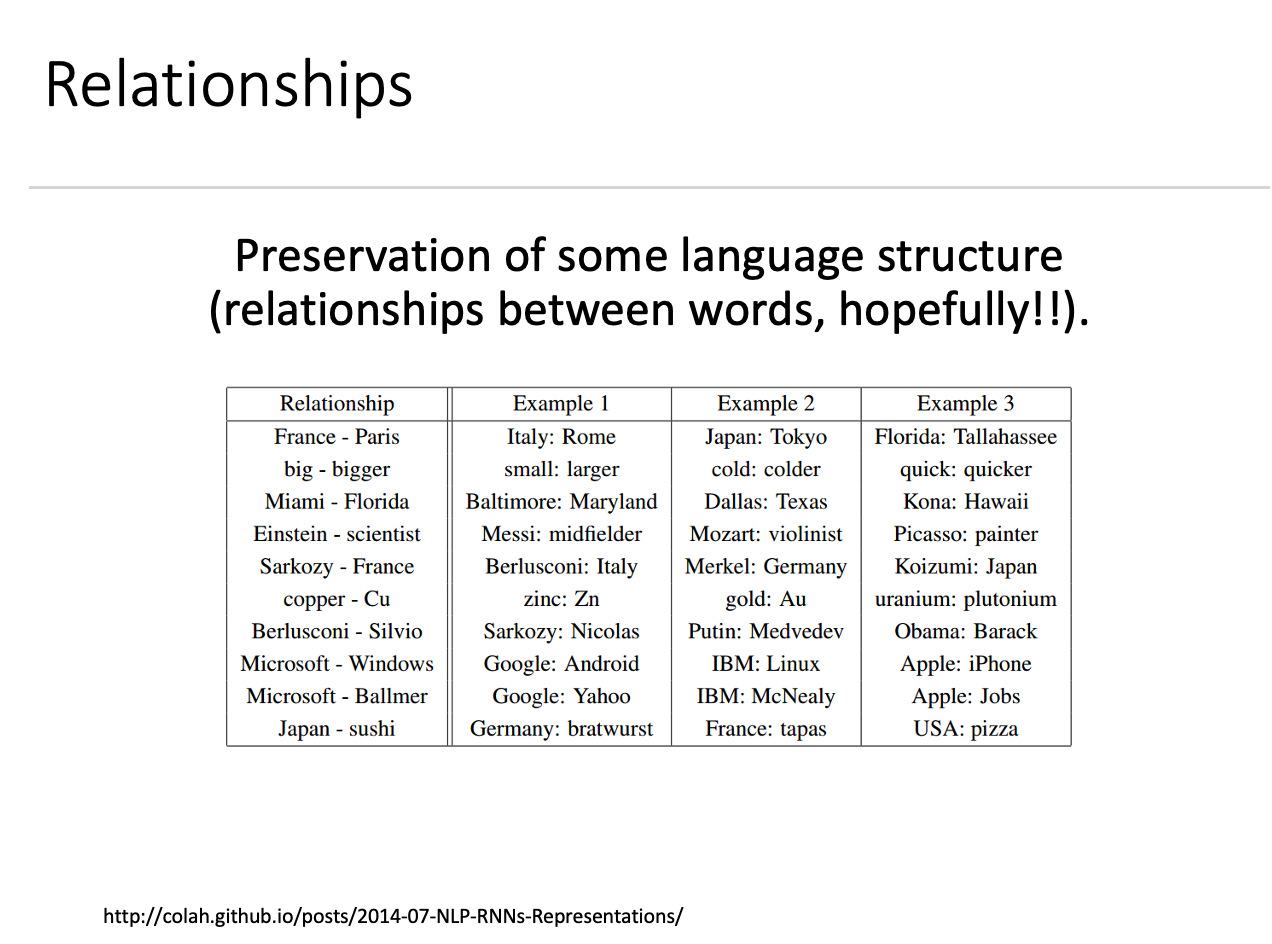
2. Word Embeddings
• 각 단어를 벡터로 표현하는 함수 $W(word)$ 설계.
• 유사한 단어는 벡터 공간에서 가까운 위치.
• 단어 간 관계는 벡터의 차이로 나타냄.
3. 임베딩 차원의 설계
• 임베딩 공간의 크기는 성능과 효율성의 균형을 고려해 설계.
• $W$는 예측 또는 분류 작업의 일부로 학습됨.
4. Word2Vec
• Continuous Bag of Words (CBOW):
• 대상 단어의 앞뒤 개의 단어 벡터를 더해 대상 단어를 예측.
• 단어 순서를 고려하지 않지만 벡터 합이 유의미한 정보 제공.








• Skip-Gram:
• 중심 단어를 사용해 주변 단어를 예측.
• 문맥 정보로 단어의 의미를 학습.



• Word2Vec의 한계:
• 학습 속도가 느리고 대량의 데이터가 필요.
• 드문 단어 학습에 어려움.
5. Word2Vec 개선점
• 단어 쌍 및 구문:
• “Boston Globe”와 같은 자주 사용되는 구문을 하나의 단어로 취급.
• 구문 처리로 어휘 크기는 증가하지만 학습 비용 감소.
• 고빈도 단어 하위 샘플링:
• “the”와 같은 고빈도 단어의 학습 샘플 수를 줄여 모델 효율성 향상.
• 선택적 업데이트:
• Negative Sampling 기법으로 네트워크 가중치 일부만 업데이트.
6. 응용
• NLP 작업:
• 개체명 인식(NER), 품사 태깅, 의미 분석 등에서 활용.
• 다중 언어 임베딩:
• 두 언어의 단어를 벡터 공간에서 정렬하여 번역 및 의미 관계 학습.
• 다중 모달 데이터:
• 이미지와 텍스트 데이터를 단일 임베딩 공간에 맵핑.
7. Beyond Words
• 단어를 넘어 문장, 단락, 문서의 의미를 벡터화.
• Doc2Vec과 같은 기법을 활용해 문서 간 유사성을 계산.

8. 대형 언어 모델
• Word embeddings은 ChatGPT와 같은 대형 언어 모델의 기초 기술.
• 모델 훈련은 다음 단어를 예측하는 방식으로 진행됨.

요약
이 강의는 임베딩 기술이 텍스트 데이터 표현과 NLP 작업에 어떻게 사용되는지를 설명하며, Word2Vec 및 확장 기법을 중심으로 데이터
벡터화의 기본 원리를 탐구한다. NLP 응용뿐만 아니라 다중 모달 데이터와 대형 언어 모델에도 활용 가능성이 크다.
'Learn > '24_Fall_(EE542) Internet&Cloud Computin' 카테고리의 다른 글
| (LAB 02) AWS Bring UP and Queuing (0) | 2025.01.09 |
|---|---|
| (LAB 01) Network with VyOS, and simple Socket Program (0) | 2025.01.09 |
| (Lecture 19) Machine Learning 2 (0) | 2025.01.09 |
| (Lecture 18) Machine Learning (1) | 2025.01.09 |
| (Lecture 17) Big Data Processing (0) | 2025.01.09 |