강의 요약: EE542 Lecture 11 - Hardware Accelerators in Cloud
이번 강의는 클라우드 환경에서 하드웨어 가속기의 활용을 중심으로, GPU(Graphics Processing Unit), FPGA(Field Programmable Gate Array), 그리고 SIMD(Single Instruction Multiple Data) 아키텍처의 응용과 성능 향상 사례를 다루었다. 이러한 기술은 클라우드의 계산 성능과 에너지 효율성을 극대화하는 데 중요한 역할을 한다.
주요 내용
1. 하드웨어 가속기의 필요성
• 빅데이터 처리 및 클라우드 기반 애플리케이션에서 계산 속도를 높이기 위해 하드웨어 가속기를 사용.
• 트레이드오프:
• 속도, 전력 소비, 칩 면적, 비용 사이의 균형.
• 주요 가속기:
• GPU, FPGA, SIMD, NSP(Native Signal Processing).
• 성능 측정:
• Amdahl's Law를 통한 병목 현상 분석
• 다양한 한드웨어 구성 요소의 성능 비교
하드웨어 가속의 성능 측정
- 성능 측정 방법:
- 최대 성능: 최적의 성능을 달성하기 위한 이론적 한계
- 실제 성능: 다양한 하드웨어 구성 요소의 성능을 측정하여 비교
- 예시 솔루션:
- Intel Optane SSD 905P: 1.5TB, (read/write)18Gbps/14Gbps, PCIe 3.0, 약 $2,000
- Western Digital Black SSD: 1TB, (read/write)30Gbps/13Gbps, PCI3 3.0 x8, 약 $220
- Crucial PCIe 4.0 M.2 SSD: 1TB, (read/write)50Gbps/40Gbps, 약 $120
2. GPU(Graphics Processing Unit)
• GPU의 주요 특징:
• 병렬 처리를 통해 고성능 계산 제공.
• CUDA(Compute Unified Device Architecture) 플랫폼에서 병렬 프로그래밍 지원.
• NVIDIA GPU 아키텍처:
• Tesla, Fermi, Kepler, Maxwell, Pascal 등 세대를 거쳐 발전.
• 최신 모델은 코어 수 증가와 에너지 효율성 개선.
• 활용 사례:
• 이미지 처리, 딥러닝, 데이터 분석.
• GPU 처리 단계:
• CPU에서 데이터를 GPU 메모리로 복사 → GPU에서 병렬 처리 → 결과를 CPU 메모리로 복사.

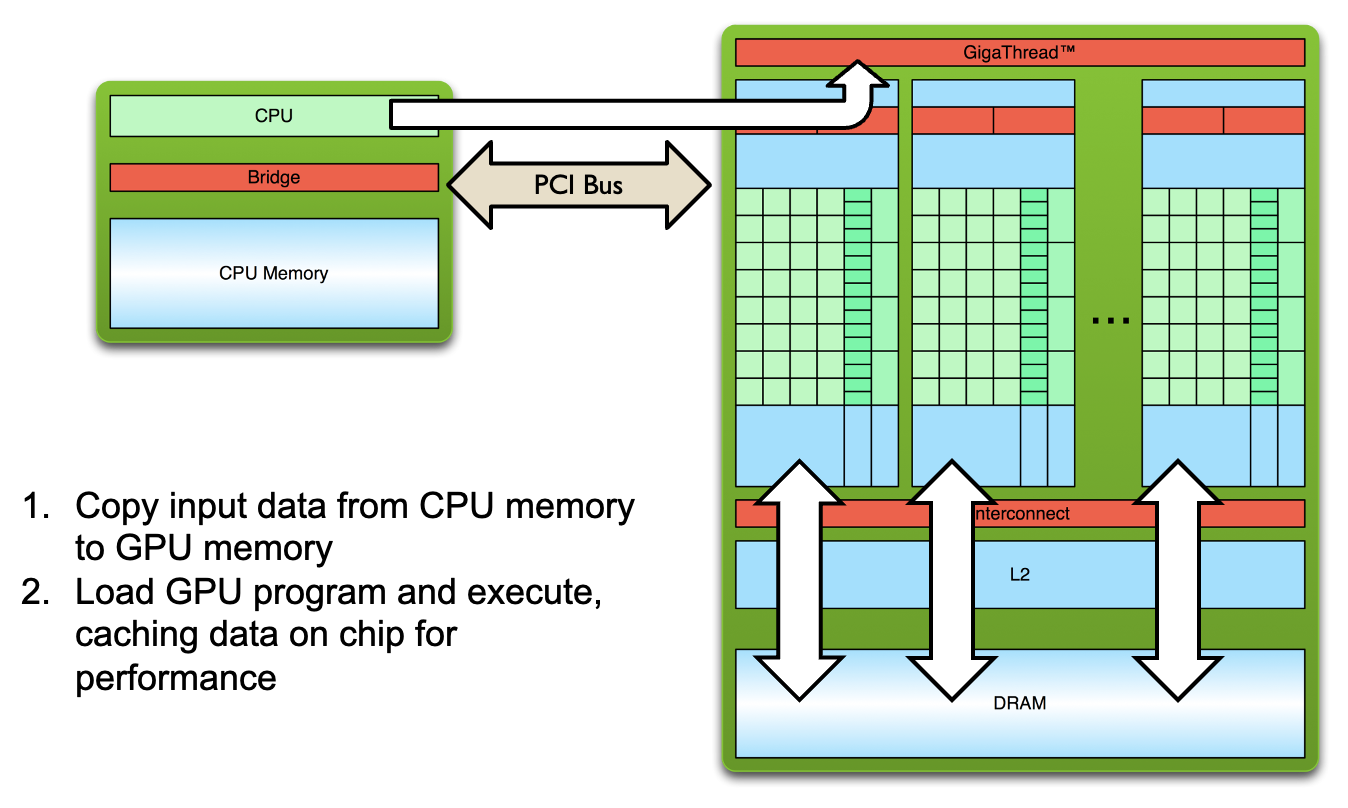


3. FPGA(Field Programmable Gate Array)
• FPGA의 특징:
• 하드웨어 논리를 프로그래밍 가능.
• 특정 애플리케이션에 최적화된 하드웨어 설계 가능.
• 장점:
• 높은 유연성과 낮은 에너지 소비.
• 연구 및 교육 목적으로 사용되며 ASIC(특정 용도용 집적 회로)로 전환 가능.
• AWS F1 인스턴스:
• FPGA를 클라우드에서 쉽게 통합하고 사용 가능.
• FPGA의 응용:
• 데이터 암호화, 네트워크 패킷 처리, 머신러닝 가속.





4. SIMD(Single Instruction Multiple Data)
• SIMD의 특징:
• 동일한 명령을 여러 데이터에 동시에 적용.
• 벡터 연산에서 높은 효율성 제공.

• 활용 사례:
• 벡터 추가, 벡터 스케일링, 벡터 내적 계산.
• Intel과 AMD의 SIMD 명령어 세트:
• Intel의 MMX, SSE, AVX.
• AMD의 3DNow!.
5. Native Signal Processing (NSP)
• OS와 통합된 하드웨어 가속.
• Intel의 AVX-512와 같은 고급 벡터 확장 지원.
• Clear Linux OS를 통해 NSP 성능 최적화.
6. 하드웨어/소프트웨어 협업 설계
• 설계 전략:
• 특정 애플리케이션에 맞게 하드웨어와 소프트웨어를 공동 설계.
• 예시:
• Spark MLlib와 FPGA 통합.
• AWS 활용:
• Spark와 FPGA의 병렬 컴퓨팅 확장.
7. 성능 평가와 한계
• 성능을 최대화하려면 병목 현상을 해결해야 함.
• 예:
• PCIe 대역폭 제한, GPU 메모리와 CPU 메모리 간 데이터 이동 병목.
• Amdahl’s Law:
• 가속기의 성능 향상은 전체 시스템 성능에 제한적으로 기여.
요약
이 강의는 클라우드 환경에서 GPU, FPGA, SIMD와 같은 하드웨어 가속기를 활용하여 성능을 최적화하는 방법을 설명한다. 이러한 기술은 병렬 처리를 통해 계산 속도를 크게 향상시키며, 클라우드 기반 데이터 처리의 핵심 도구로 자리 잡았다.
보충
Amdahl’s Law: 성능 향상 한계 설명
- 성능 향상 후 실행 시간:
$ExTime_{new} = ExTime_{old} \times \left[ (1 - Fraction_{enhanced}) + \frac{Fraction_{enhanced}}{Speedup_{enhanced}} \right]$
• $ExTime_{new}$: 성능 향상 후 실행 시간.
• $ExTime_{old}$: 성능 향상 전 실행 시간.
• $Fraction_{enhanced}$: 성능 향상이 적용된 작업의 비율.
• $Speedup_{enhanced}$: 성능 향상이 적용된 부분의 가속 비율.
- 전체 성능 향상 비율:
$Speedup_{overall} = \frac{ExTime_{old}}{ExTime_{new}} = \frac{1}{(1 - Fraction_{enhanced}) + \frac{Fraction_{enhanced}}{Speedup_{enhanced}}}$
• 전체 시스템의 성능 향상을 나타냄.
- 최대 성능 향상 (이론적 한계):
$Speedup_{maximum} = \frac{1}{1 - Fraction_{enhanced}}$
• $Speedup_{maximum}$: 병렬화가 가능한 비율이 높더라도 직렬화된 작업 때문에 성능 향상이 제한적임을 나타냄.
• Amdahl’s Law 핵심:
• 병렬화 가능한 작업 ($Fraction_{enhanced}$)의 비율이 크더라도, 병렬화가 불가능한 직렬 작업 ($1 - Fraction_{enhanced}$)이 전체 성능에 제약을 가함.
• 병렬 프로세서가 많아질수록 $Speedup_{enhanced}$는 증가하지만, $(1 - Fraction_{enhanced})$의 영향을 제거할 수 없음.
• 그래픽 요소:
• 녹색(병렬화 가능)과 주황색(직렬 처리) 부분을 통해 병렬 처리 비율이 성능 향상에 미치는 시각적 효과를 보여줌.
Amdahl’s Law는 병렬 컴퓨팅의 성능 향상에 직렬 작업이 미치는 한계를 강조합니다. 이를 통해 하드웨어 설계나 소프트웨어 최적화 시 현실적인 기대치를 설정할 수 있습니다.
'Learn > '24_Fall_(EE542) Internet&Cloud Computin' 카테고리의 다른 글
| (Lecture 13) Network with RDMA (0) | 2025.01.08 |
|---|---|
| (Lecture 12) Logic, Memory, and Reconfigurable Hardware Accelerators (0) | 2025.01.08 |
| (Lecture 10) Uses of Cloud (0) | 2025.01.08 |
| (Lecture 9) Cloud Computing (0) | 2025.01.08 |
| (Lecture 8) Single Processor to Cloud (0) | 2025.01.08 |